Stable Diffusion Web - Accueil
 Stable
Diffusion Web est une plateforme en
ligne permettant de générer des images et des
vidéos à partir de texte ou d’images,
basée sur la technologie Stable
Diffusion.
Stable
Diffusion Web est une plateforme en
ligne permettant de générer des images et des
vidéos à partir de texte ou d’images,
basée sur la technologie Stable
Diffusion.
le site, https://stablediffusionweb.com/fr ou https://stablediffusionweb.com/fr/app
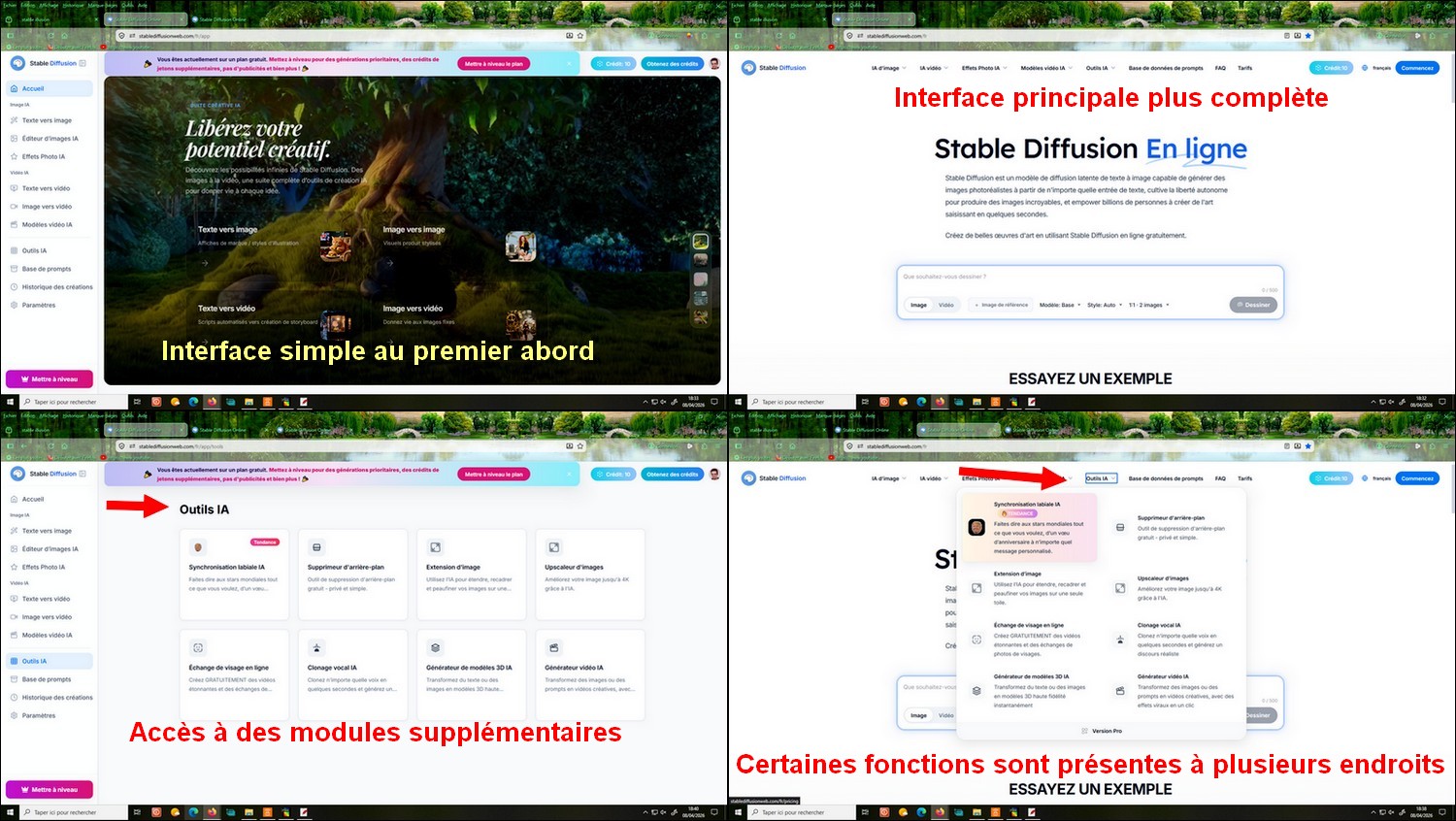
- L’outil propose
une interface simple d’accès, avec des
fonctionnalités comme la génération d’images,
la transformation d’images
(image-to-image) et la création de
vidéos à partir de deux images.
- Interface simple au départ, mais organisation plus complexe avec plusieurs menus et outils similaires, certaines fonctionnalités demandent un peu d’exploration et ne sont pas toujours immédiatement visibles.
- La génération de vidéos peut se faire de deux manières : directement via les fonctions intégrées de la plateforme Stable Diffusion Web, ou indirectement via des outils externes ou modules spécifiques.
- Certaines fonctionnalités comme le Face Swap ou la génération vidéo peuvent être accessibles gratuitement, mais elles sont généralement limitées (crédits, durée, qualité ou vitesse).
 |
|
|
- Le système
fonctionne avec des crédits :
* 10 crédits gratuits par jour (version gratuite), sinon, abonnements mensuels avec crédits supplémentaires
Une image coûte généralement 1 ou 2 crédits, tandis que
la génération de vidéo est plus gourmande (environ 5 crédits, jusqu'à 20).
Points forts :
* accessible directement en ligne, sans installation
* prise en main rapide
* fonctionnalités vidéos intéressantes
- Points
faibles :
* crédits limités en version gratuite
* interface parfois peu intuitive (notamment pour certaines étapes
comme l’ajout d’une seconde image) ****
* dépendance au système de crédits
* affichage d'un filigrane
Idéal pour :
* tester la génération d’images et de vidéos IA
* utilisateurs débutants ou occasionnels
 rappel : même gratuit, il
faut avoir un compte Microsoft ,
Google, etc..
rappel : même gratuit, il
faut avoir un compte Microsoft ,
Google, etc..
- A créer une
image à partir d'un texte, 1
crédit, avec ce prompt : un chat
sur une moto avec un blouson de cuir noir, dans
une cité en ruines, envahie par de la
végétation,
des fougères géantes, des plantes rampantes, avec des couleurs technicolor
j'ai dû faire 2 essais pour avoir le chat, et non un humain sur la moto, StableDiffusion, contrairement aux autres IA, “corrige” le prompt inconsciemment et remplace le chat par un humain
comment corriger (important), il faut forcer l’IA avec le prompt amélioré : un chat sur une moto, un animal, félin, sans humain, etc...
 |
- B créer une image à partir d'une image, 2 crédits, avec ce prompt : transformer cette photo en une image style cartoon, en ajoutant un arrière-plan forestier
|
 |

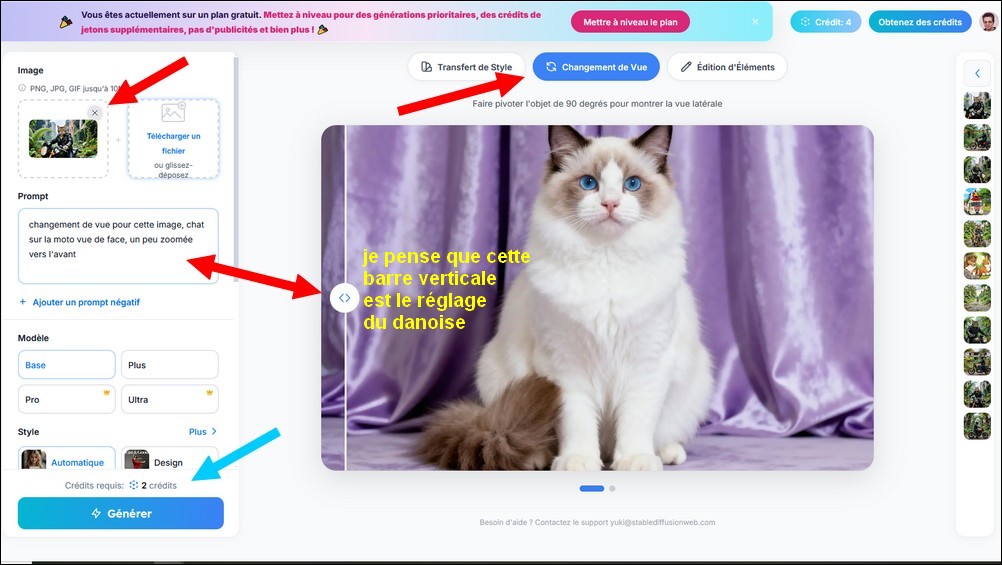
- C modifier une image, 2 crédits, dans Editeur d'image IA, avec ce prompt : changement de vue pour cette image (créée au point A), chat sur la moto vue de face, un peu zoomée vers l'avant
 |
|

 La
Théorie
La
Théorie- modifier
une image en téléversant une ou deux images de
plus, dans Editeur d'image IA (vu
au point C) D
objectif, créer 2 variantes de l'image1 de base, les combiner dans l'Editeur d'image IA
- explications
- la 1ère image (obligatoire) est l'image de base
- la 2e
image (image de référence), influence
comment l’image doit être rendue, elle sert
souvent à :
donner Style visuel, ex : peinture, anime, photo réaliste, illustration
un style d’un personnage, ex : garder une identité / visage cohérent
une ambiance / éclairage, ex : coucher de soleil, néon, sombre, etc.
- la 3e
image (contrôle supplémentaire),
influence la structure, pas seulement le style
Elle sert à renforcer ou préciser :
la composition (pose, cadrage)
la perspective
la posture ou structure du sujet
l'architecture ou structure d’un décor
- La
pratique
- étapes de créations de 2 images à partie de l'image1 : ne pas faire 3 images “différentes” mais 3 versions contrôlées du même monde
- Étape
1 > créer 2 variantes (images) de la base
partir toujours de l'image1 (chat sur moto).
puis faire 2 générations : image2 et image 3:
- Étape
2 > combiner les 3 images
Image 1 > base
Image 2 > Style
Image 3 > Structure
- variante
Image 2 > Style
modifier uniquement :
couleurs (technicolor, néon, etc.)
lumière (cinéma, volumétrique)
ambiance (post-apo, surréaliste)
ne pas modifier:
pose du chat
moto
composition
- prompt
:
éclairage post-apocalyptique en Technicolor, ambiance dramatique, lumière volumétrique, contraste élevé, couleurs surréalistes, image fixe de film, style concept art
- variante
Image 3 > Structure
modifier uniquement :
réalisme du chat
détails de la moto
précision des ruines / végétation
ne pas modifier:
style global
ambiance colorimétrique (ou très peu)
- prompt
:
chat très détaillé sur une moto, anatomie réaliste, blouson en cuir détaillé, moto en métal rouillé, ruines envahies par la végétation, fougères géantes, netteté impeccable, scène physiquement cohérente
 |
Image 1 de base |
 |
Image 2 |
 |
Image 3, bien plus nette que l'image1 |
- avec l'image1 de base du
chat sur une moto avec un blouson de cuir noir,
dans une cité en ruines, envahie par de la
végétation,
des fougères géantes, des plantes rampantes, avec des couleurs technicolor
- Note
préalable
Les explications suivantes présentent un fonctionnement théorique de Stable Diffusion pour comprendre les principes des variantes (style, structure, combinaison).
Dans la pratique, le comportement du modèle peut être différent selon les paramètres et les images utilisées.
Voir les exemples et tests plus bas pour les résultats réels observés.
- Étape
3 > utilisation pour Transfert de
Style
image1 + image2
- Prompt
:
Appliquer un style cinématographique Technicolor, conserver la composition identique, préserver le chat sur la moto, améliorer l'éclairage et l'ambiance, ultra détaillé, qualité cinématographique
- Étape
3 > utilisation pour Edition d'éléments
image1 + image3
- Prompt
:
Amélioration de la précision anatomique et structurelle, renforcement du réalisme du chat et des détails de la moto, optimisation de l'environnement, conservation de la composition originale
- Étape
3 > utilisation pour Changement
de vue, abordée au point C
le changement de vue s’effectue à partir d’une seule image1, accompagnée d’un prompt décrivant l’angle souhaité.
- Prompt
: pour améliorer le
résultat, utiliser des termes comme :
“vue de profil”
“vue de côté”
“angle 3/4”
“vue arrière”
- Étape
3 > utilisation finale pour Edition d'éléments
image1 + image2 + image3
- Prompt
:
Scène cinématographique post-apocalyptique en technicolor, un chat à moto dans une ville en ruines envahie par des plantes géantes, ultra détaillée, matériaux réalistes, éclairage dramatique, grande cohérence, qualité d'illustration conceptuelle
Transfert de Style ressemble à l'image 2 avec ajout d'un élément sur la moto |
 |
Edition d'éléments ressemble à l'image 3 |
 Retours
d’expérience
Retours
d’expérience- Stable
Diffusion ne fusionne pas réellement
plusieurs images : il privilégie souvent une
seule référence dominante, voir mes images ci-dessus
pour de meilleurs résultats, il vaut mieux travailler simplement, avec des variantes ciblées et des réglages modérés, plutôt que de combiner trop d’images en une seule génération.
- A
éviter avec les variantes “trop parfaites”
Ne créez pas des images de référence trop abouties (style ou structure).
Sinon, Stable Diffusion ne les combine pas : il les remplace.
Résultat : voir mes images ci-dessus
1 + 2 = 2
1 + 3 = 3
1 + 2 + 3 > instable ou inutile > voir plus bas Bonnes pratiques pour éviter les erreurs
Les variantes doivent guider, pas être des images finales.
- Créer
des variantes utiles (pas “parfaites”)
Pour éviter qu’une image remplace les autres, vos variantes doivent rester incomplètes et ciblées :
Variante style (Image 2)
* poussez les couleurs et la lumière
* mais gardez peu de précision dans les détails
Variante structure (Image 3)
* améliorez formes et objets
* mais restez neutre sur le style et l’ambiance
Réglage clé
* utilisez un denoise modéré (pas trop élevé)
Une bonne variante guide un aspect, sans devenir une image finale parfaite.
- Un denoise (ou denoising
strength) dans Stable Diffusion, c’est
simplement le niveau de transformation de ton
image de base > Denoise = puissance de
transformation
denoise faible (0.2 ? 0.35) = on respecte l’image, changements légers (style, lumière) > idéal pour Transfert de style
denoise moyen (0.35 ? 0.6) = modifie certains détails, peut ajouter des objets / ajuster formes > idéal pour Image 3 (structure / édition)
denoise élevé (0.7 ? 1.0) = change presque tout, peut déformer la scène > résultat souvent imprévisible
- Bonnes
pratiques pour éviter les erreurs
- Pour limiter
les problèmes de fusion entre images, il est
préférable de procéder par étapes plutôt que
de tout combiner en une seule fois.
Par exemple : image1 + image2 (style) puis résultat + image3 (détails) fonctionne mieux que image1 + image2 + image3 directement.
Cette approche progressive permet au modèle de conserver une base stable et d’intégrer chaque modification sans conflit.
utilisation finale |
- à lire si
on veut approfondir, sinon, sauter au point E
- 1) Prompt pour
Transfert de style
Objectif : garder le contenu de l’image, mais changer le style artistique
Prompt type : appliquer le style de l'image de référence, conserver la composition, préserver les détails, rendu stylisé, haute qualité, éclairage homogène
Exemples :
** Style peinture : « Style peinture à l'huile, coups de pinceau impressionnistes, toile texturée, éclairage doux, rendu artistique, respect de la composition originale »
** Style anime : « Style anime, traits nets, ombrage cell-shading, couleurs vives, yeux détaillés, respect de la mise en scène originale »
** Style photo réaliste : « Photoréaliste, reflex numérique, éclairage naturel, détails nets, profondeur de champ,texture de peau réaliste »
- 2) Prompt pour
Changement de vue
Objectif : changer angle de caméra ou perspective
Prompt type : même sujet, angle de caméra différent, nouveau point de vue, changement de perspective, structure 3D cohérente, identité préservée
Exemples :
** Vue de côté : « Vue latérale, profil, même sujet, proportions harmonieuses, éclairage cinématographique »
** Vue aérienne : « Vue plongeante, perspective aérienne, vue à vol d'oiseau, environnement visible, profondeur de champ »
** Vue basse (contre-plongée) : « Prise de vue en contre-plongée, perspective dramatique, effet grand angle »
- 3) Prompt pour
Édition d’images
Objectif : Modifier une partie précise sans casser le reste
Prompt type : modifiez uniquement la zone spécifiée, tout le reste reste inchangé : intégration transparente, fusion naturelle
Exemples :
** Ajouter un objet : « Ajouter un sac à dos rouge au personnage, éclairage réaliste, ombres cohérentes, en harmonie avec l'environnement »
** Modifier les vêtements : « Changer les vêtements pour une veste moderne, conserver le visage et la pose, tissu réaliste, plis naturels »
** Modifier le décor : « Remplacer l'arrière-plan par une ville nocturne, néons, conserver le sujet, profondeur cohérente »
- E créer une
vidéo à partir d'un texte, 5
crédits, avec ce prompt : faire
défiler des mannequins squelettes, habillées de
robes noires élégantes,
chaussées de chaussures à talons, coiffées de chapeaux extravagants, sur un podium, dans un magasin de vêtements
Dans ce cas précis,
inefficace, ce résultat après 2 essais (même
problème qu'au point A), coût, 10
crédits, par contre, c'est accompagné d'un fond
musical
La présence d’un fond sonore n’est pas systématique. Certaines vidéos incluent automatiquement de la musique, tandis que d’autres sont générées sans audio, selon le module utilisé.
le prompt corrigé : mannequins squelettes, corps entièrement composés d’os, visages de crânes visibles, aucun humain, défilant sur un podium de mode, portant des robes noires élégantes, talons hauts, chapeaux extravagants, défilé de mode dans une boutique de vêtements, éclairage professionnel, scène réaliste, haute qualité
même corrigé, pas obtenu ce que je voulais, conclusion, la génération vidéo à partir d’un simple texte reste limitée, notamment pour des scènes complexes ou atypiques.
Utilisez
le bouton VIDEO pour ouvrir la vidéo en plein
écran dans un nouvel onglet.  |
- Les prompts complexes sont mieux
interprétés par certaines IA (comme
Qwen ou Flow),
avec Stable Diffusion, il est
souvent préférable de simplifier la
demande ou de procéder en
plusieurs étapes
quand le cas où créer une vidéo à partir d'un texte ne donne pas un résultat satisfaisant :
conseil : créer d'abord l'image, ensuite, créer la vidéo à partir de l'image générée, mais on n'est plus dans le cas : créer une vidéo à partir d'un texte
- F créer une
vidéo à partir d'une image (créée au
point point A), 5 crédits,
avec ce prompt : Un chat
tigré réaliste, vêtu d'un blouson de cuir noir
de motard
et de lunettes de protection, chevauche une moto vintage (vue arrière), s'éloignant sur une route défoncée. Dans une ville abandonnée envahie par la végétation,
mêmes bâtiments en ruine recouverts de végétation, même environnement, éclairage cinématographique, scène très détaillée et cohérente.
Utilisez le bouton VIDEO
pour ouvrir la vidéo en plein écran dans un
nouvel onglet. |
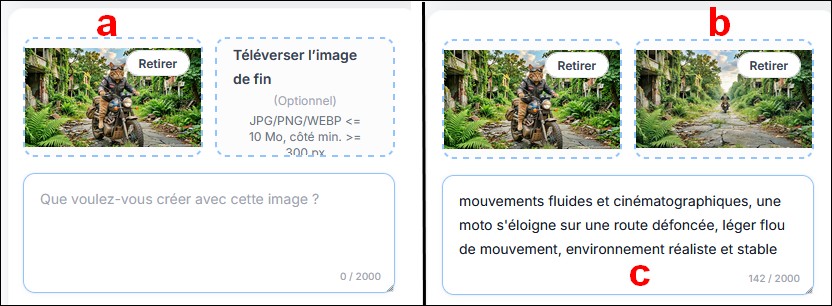
- G créer une
vidéo à partir de deux images (Frames),
5 crédits, avec ce prompt :
mouvements fluides et cinématographiques, une moto s'éloigne sur une route défoncée, léger flou de mouvement, environnement réaliste et stable
**** rappel : interface parfois peu intuitive (notamment pour certaines étapes comme l’ajout d’une seconde image)
dans le menu, sélectionner Image vers vidéo
a Téléverser l'image A > Recadrer l'image, Terminer
l'interface apparaît avec l'emplacement pour 2 images, dont une vignette vide avec des pointillés
b Téléverser l'image B > Recadrer l'image, Terminer
c écrire le prompt, mouvements fluides et cinématographiques, une moto s'éloigne sur une route défoncée, léger flou de mouvement, environnement réaliste et stable
pour résumer, le second emplacement d’image n’apparaît qu’après validation de la première image, valable également pour le point D
|
|
|


- l'accès
à des modules supplémentaires est intéressant
: Outils IA
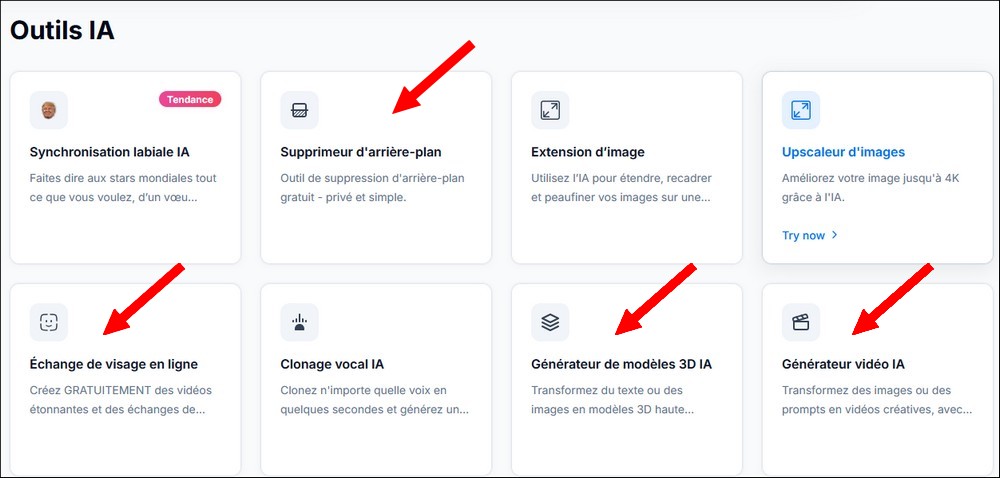 |
- 1 Supprimer l'arrière-plan de l'image (créée au point A)
 |
- 2 Echange de visage en ligne (Face Swap) : transformer des photos, l'ordre des 2 photos est important, le résultat s'adapte à la photo proposée en premier
 |
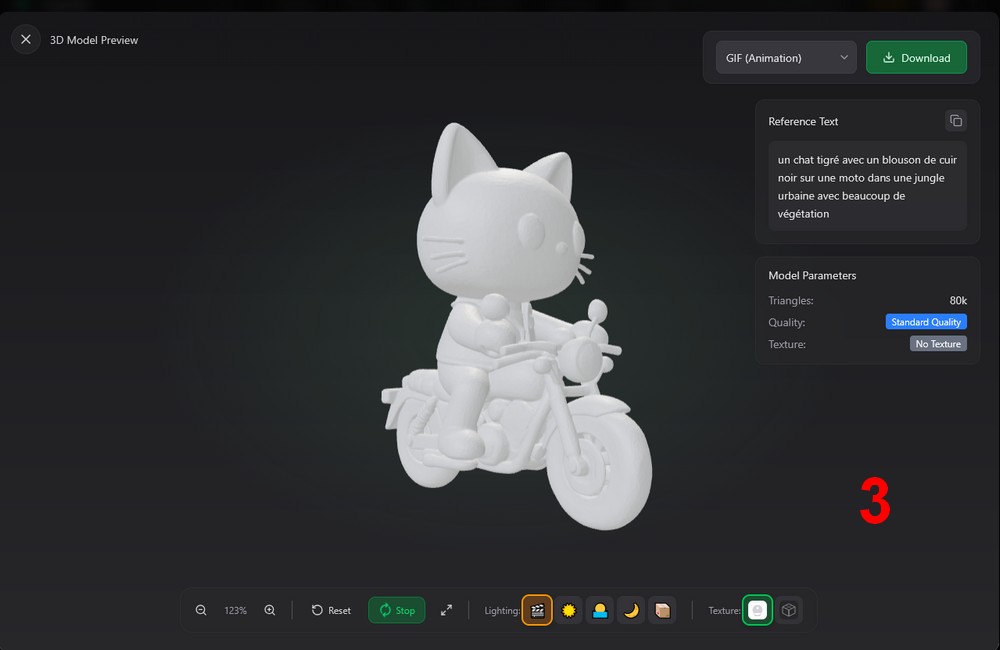
- 3
Générateur de modèles 3D IA, à partir de l'image (créée au
point A) ou d'un
texte
crée des modèles aux formats OBJ, GIF, GLB, WRBM, lisibles avec des applications comme 3D Bulder, Paint 3D, VLC, une visionneuse 3D, P3DO Explorer, DAZ Studio..
 |
|
3 |
|

- 4 Générateur vidéo IA à partir de l'image (créée au point A) sans prompt, mais à partir de l'image (créée au point A) , ou avec prompt (celui du point E)
4 |
Utilisez le bouton VIDEO
pour ouvrir la vidéo en plein écran dans un
nouvel onglet. |
4 |
Utilisez le bouton VIDEO
pour ouvrir la vidéo en plein écran dans un
nouvel onglet. |
- A retenir
- Stable
Diffusion peut être complexe à
maîtriser, mais reste un outil très riche et
puissant.
Une fois les principes de base compris (variantes, denoise, approche progressive), il permet un contrôle très fin et créatif des images, aussi des vidéos.

(Enregistrer cette page par "Fichier / Enregistrer sous..." pour utiliser ce tutoriel même déconnecté !)